

Alpha Notice: These docs cover the v1-alpha release. Content is incomplete and subject to change.For the latest stable version, see the v0 LangChain Python or LangChain JavaScript docs.
1.0 Alpha releases are available for most packages. Only the following currently support new content blocks:
langchainlangchain-corelangchain-anthropiclangchain-awslangchain-openailangchain-google-genailangchain-ollama
create_agent
A new standard way to build agents in LangChain, replacing
langgraph.prebuilt.create_react_agent with a cleaner, more powerful API.Standard content blocks
A new
.content_blocks property that provides unified access to modern LLM features across all providers.LangChain Classic
Legacy functionality has moved to
langchain-classic to keep the core package focused on the most important agent building blocks.create_agent
create_agent is the standard way to build agents in LangChain 1.0. It provides a simpler interface than langgraph.prebuilt.create_react_agent while offering greater customization potential through middleware.
Middleware
Middleware is the defining feature ofcreate_agent. It makes create_agent highly customizable, raising the ceiling for what you can build.
Great agents require context engineering: getting the right information to the model at the right time. Middleware helps you control dynamic prompts, conversation summarization, selective tool access, state management, and guardrails through a composable abstraction.
Prebuilt middleware
LangChain provides a few prebuilt middlewares for common patterns, including:- PIIRedactionMiddleware: Redact sensitive information before sending to the model
- SummarizationMiddleware: Condense conversation history when it gets too long
- HumanInTheLoopMiddleware: Require approval for sensitive tool calls
Custom middleware
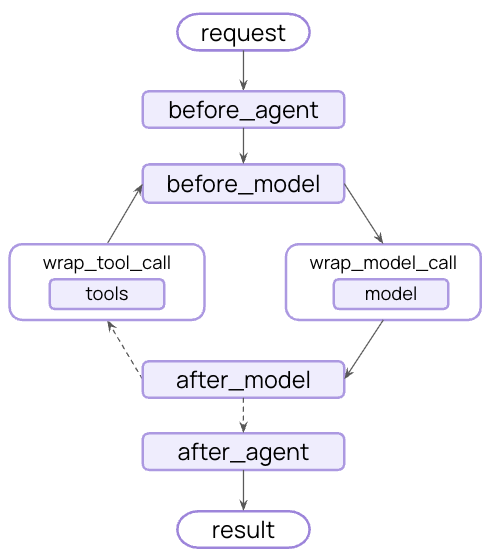
You can also build custom middleware to fit your specific needs. Build custom middleware by implementing any of these hooks on a subclass of theAgentMiddleware class:
| Hook | When it runs | Use cases |
|---|---|---|
before_agent | Before calling the agent | Load memory, validate input |
before_model | Before each LLM call | Update prompts, trim messages |
wrap_model_call | Around each LLM call | Intercept and modify requests/responses |
wrap_tool_call | Around each tool call | Intercept and modify tool execution |
after_model | After each LLM response | Validate output, apply guardrails |
after_agent | After agent completes | Save results, cleanup |
Built on LangGraph
Becausecreate_agent is built on LangGraph, you automatically get built in support
for long running, reliable agents via:
Persistence
Conversations automatically persist across sessions with built-in checkpointing
Streaming
Stream tokens, tool calls, and reasoning traces in real-time
Human-in-the-loop
Pause agent execution for human approval before sensitive actions
Time travel
Rewind conversations to any point and explore alternate paths and prompts
Structured output
create_agent has improved structured output generation:
- Main loop integration: Structured output is now generated in the main loop instead of requiring an additional LLM call
- Structured output strategy: Models can choose between calling tools or using provider-side structured output generation
- Cost reduction: Eliminates extra expense from additional LLM calls
handle_errors parameter to ToolStrategy:
- Parsing errors: Model generates data that doesn’t match desired structure
- Multiple tool calls: Model generates 2+ tool calls for structured output schemas
Standard content blocks
The new.content_blocks property provides unified access to modern LLM features across all providers:
Benefits
- Provider agnostic: Access reasoning traces, citations, built-in tools (web search, code interpreters, etc.), and other features using the same API regardless of provider
- Future proof: New LLM capabilities are automatically available through content blocks
- Type safe: Full type hints for all content block types
- Backward compatible: Standard content can be loaded lazily, so there are no associated breaking changes
langchain-classic
LangChain v1 focuses on standard interfaces and production-ready agents. Legacy functionality has moved to langchain-classic to keep the core package lean.
What’s in langchain-classic
- Legacy chains and chain implementations
- The indexing API
langchain-communityexports- Other deprecated functionality
langchain-classic:
Reporting issues
Please report any issues discovered with 1.0 on GitHub using the'v1' label.
Additional resources
LangChain 1.0
Read the announcement
Middleware Guide
Deep dive into middleware
Agents Documentation
Full agent documentation
Message Content
New content blocks API
Migration guide
How to migrate to LangChain v1
GitHub
Report issues or contribute
See also
- Versioning - Understanding version numbers
- Release policy - Detailed release policies